前言
真没想到,距离视频生成上一轮的集中爆发(详见《Sora之前的视频生成发展史:从Gen2、Emu Video到PixelDance、SVD、Pika 1.0》)才过去三个月,没想OpenAI一出手,该领域又直接变天了
自打2.16日OpenAI发布sora以来(其开发团队包括DALLE 3的4作Tim Brooks、DiT一作Bill Peebles、三代DALLE的核心作者之一Aditya Ramesh等13人),不但把同时段Google发布的Gemini 1.5干没了声音,而且网上各个渠道,大量新闻媒体、自媒体(含公号、微博、博客、视频)做了大量的解读,也引发了圈内外的大量关注
很多人因此认为,视频生成领域自此进入了大规模应用前夕,好比NLP领域中GPT3的发布
一开始,我还自以为视频生成这玩意对于有场景的人,是重大利好,比如在影视行业的
对于没场景的人,只能当热闹看看,而且我司大模型项目开发团队去年年底还考虑过是否做视频生成的应用,但当时想了好久,没找到场景,做别的应用去了
可当我接连扒出sora相关的10多篇论文之后,觉得sora和此前发布的视频生成模型有了质的飞跃(不只是一个60s),而是再次印证了大力出奇迹,大模型似乎可以在力大砖飞的情况下开始理解物理世界了,使得我司大模型项目组也愿意重新考虑开发视频生成的相关应用
本文主要分为三个部分(初步理解只看第一部分即可,深入理解看第二部分,更多细节则看第三部分)
第一部分,侧重sora的核心技术解读
方便大家把握重点,且会比一切新闻稿都更准确,此外
 如果之前没有了解过DDPM、ViT的,建议先阅读下此文《从VAE、扩散模型DDPM、DETR到ViT、Swin transformer》
如果之前没有了解过DDPM、ViT的,建议先阅读下此文《从VAE、扩散模型DDPM、DETR到ViT、Swin transformer》
如果之前没有了解过图像生成的,建议先阅读下此文《从CLIP到DALLE1/2、DALLE 3、Stable Diffusion、SDXL Turbo、LCM》
当然,如果个别朋友实在不想点开看上面的两篇文章,我也尽可能在本文中把相关重点交代清楚
第二部分,侧重sora相关技术的发展演变
把sora涉及到的关键技术在本文中全部全面、深入、细致的阐述清楚,毕竟如果人云亦云就不用我来写了
且看完这部分你会发现,从来没有任何一个火爆全球的产品是一蹴而就的,且基本都是各种创新技术的集大成者(Google很多工作把transformer等各路技术发扬光大,但OpenAI则把各路技术 整合到极致了..)
第三部分,根据sora的32个reference以窥探其背后的更多细节
由于sora实在是太火了,网上各种解读非常多,有的很专业,有的看上去一本正经 实则是胡说八道(即便他的title看起来有一定的水平),为方便大家辨别什么样的解读是不对的,特把一些更深入的细节也介绍下
第一部分 OpenAI Sora的关键技术点
1.1 Sora的三大Transformer组件
1.1.1 从前置工作DALLE 2到sora的三大组件
为方便大家更好的理解sora背后的原理,我们先来快速回顾下AI绘画的原理(理解了AI绘画,也就理解了sora一半)
以DALLE 2为例,如下图所示(以下内容来自此文:从CLIP到DALLE1/2、DALLE 3、Stable Diffusion、SDXL Turbo、LCM)
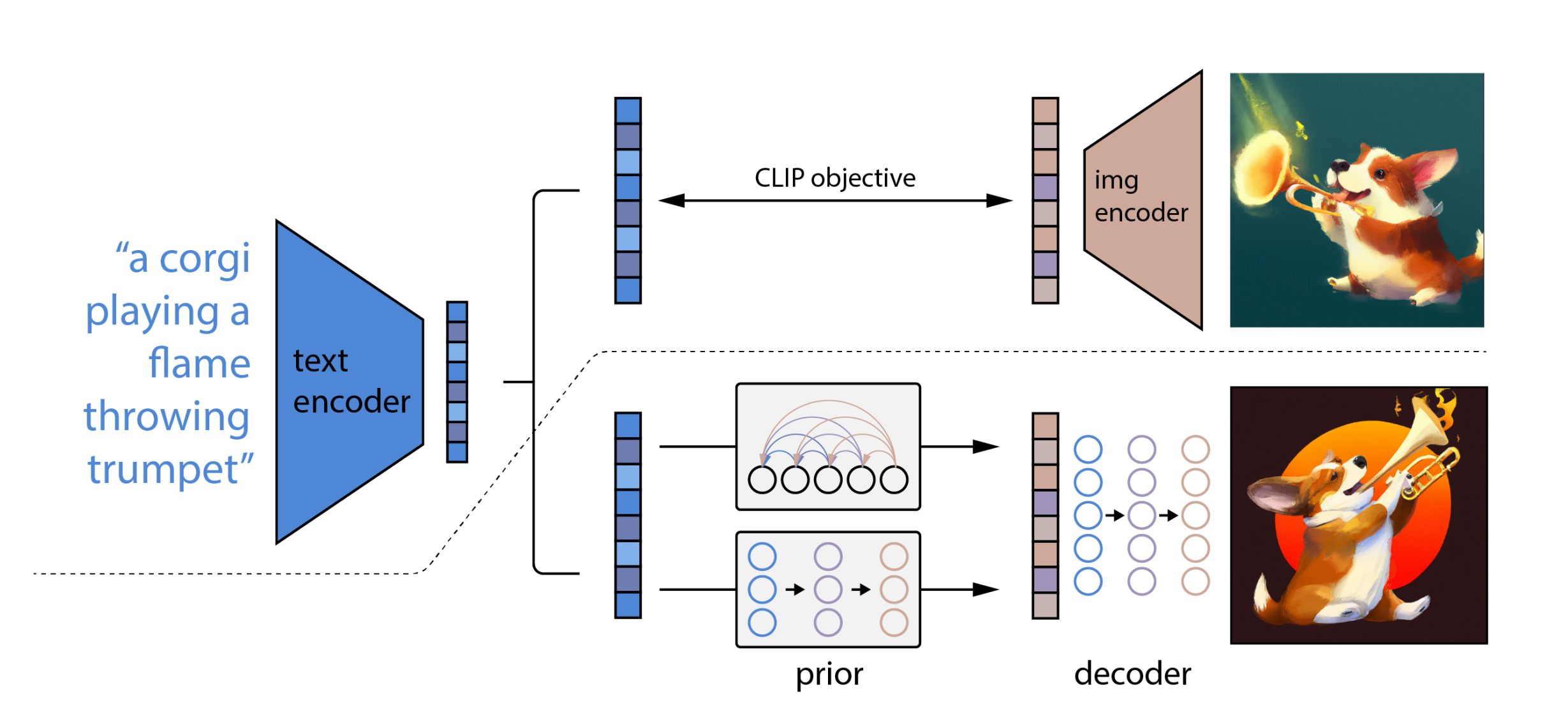
CLIP训练过程:学习文字与图片的对应关系
如上图所示,CLIP的输入是一对对配对好的的图片-文本对(根据对应文本一条狗,去匹配一条狗的图片),这些文本和图片分别通过Text Encoder和Image Encoder输出对应的特征,然后在这些输出的文字特征和图片特征上进行对比学习
DALL·E2:prior + decoder
上面的CLIP训练好之后,就将其冻住了,不再参与任何训练和微调,DALL·E2训练时,输入也是文本-图像对,下面就是DALL·E2的两阶段训练:
阶段一 prior的训练:根据文本特征(即CLIP text encoder编码后得到的文本特征),预测图像特征(CLIP image encoder编码后得到的图片特征)
换言之,prior模型的输入就是上面CLIP编码的文本特征,然后利用文本特征预测图片特征(说明白点,即图中右侧下半部分预测的图片特征的ground truth,就是图中右侧上半部分经过CLIP编码的图片特征),就完成了prior的训练
推理时,文本还是通过CLIP text encoder得到文本特征,然后根据训练好的prior得到类似CLIP生成的图片特征,此时图片特征应该训练的非常好,不仅可以用来生成图像,而且和文本联系的非常紧(包含丰富的语义信息)
阶段二 decoder生成图:常规的扩散模型解码器,解码生成图像
这里的decoder就是升级版的GLIDE(GLIDE基于扩散模型),所以说DALL·E2 = CLIP + GLIDE
所以对于DALLE 2来说,正因为经过了大量上面这种训练,所以便可以根据人类给定的prompt画出人类预期的画作,说白了,可以根据text预测画作长什么样
最终,sora由三大Transformer组件组成(如果你还不了解transformer或注意力机制,请读此文):Visual Encoder(即Video transformer,类似下文将介绍的ViViT)、Diffusion Transformer、Transformer Decoder,具体而言
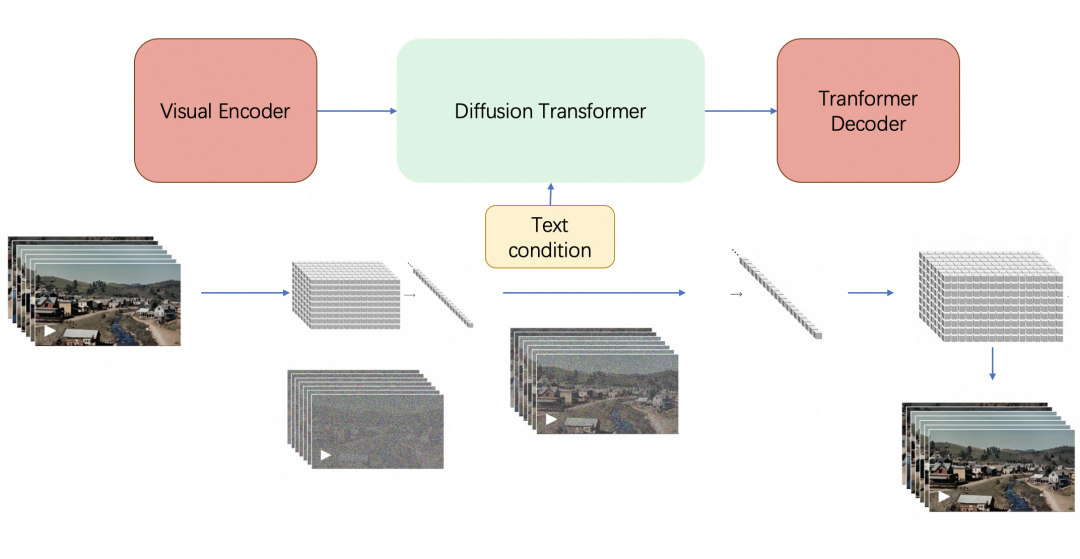
训练中,给定一个原始视频
Visual Encoder将视频压缩到较低维的潜在空间(潜在空间这个概念在stable diffusion中用的可谓炉火纯青了,详见此文的第三部分)
然后把视频分解为在时间和空间上压缩的潜在表示(不重叠的3D patches),即所谓的一系列时空Patches
再将这些patches拉平成一个token序列,这个token序列其实就是原始视频的表征:visual token序列
Sora 在这个压缩的潜在空间中接受训练,还是类似扩散模型那一套,先加噪、再去噪
这里,有两点必须注意的是
1 扩散时卷积结构U-net被替换成了transformer结构的DiT(加之视觉元素转换成token之后,transformer擅长长距离建模,下文详述DiT)
2 视频中这一系列帧在上个过程中是同时被编码的,去噪也是一系列帧并行去噪的(每一帧逐步去噪、多帧并行去噪)
此外,去噪过程中,可以加入去噪的条件(即text condition),这个去噪条件可以是原始视频的描述,也可以是二次创作的prompt
比如可以将visual tokens视为query,将text tokens作为key和value,然后类似SD那样做cross attention
OpenAI 还训练了相应的Transformer解码器模型,将生成的潜在表示映射回像素空间,从而生成视频
你会发现,上述整个过程,其实和SD的原理是有较大的相似性(SD原理详见此文《从CLIP到DALLE1/2、DALLE 3、Stable Diffusion、SDXL Turbo、LCM》的3.2节),当然,不同之处也有很多,比如视频需要一次性还原多帧、图像只需要还原一帧
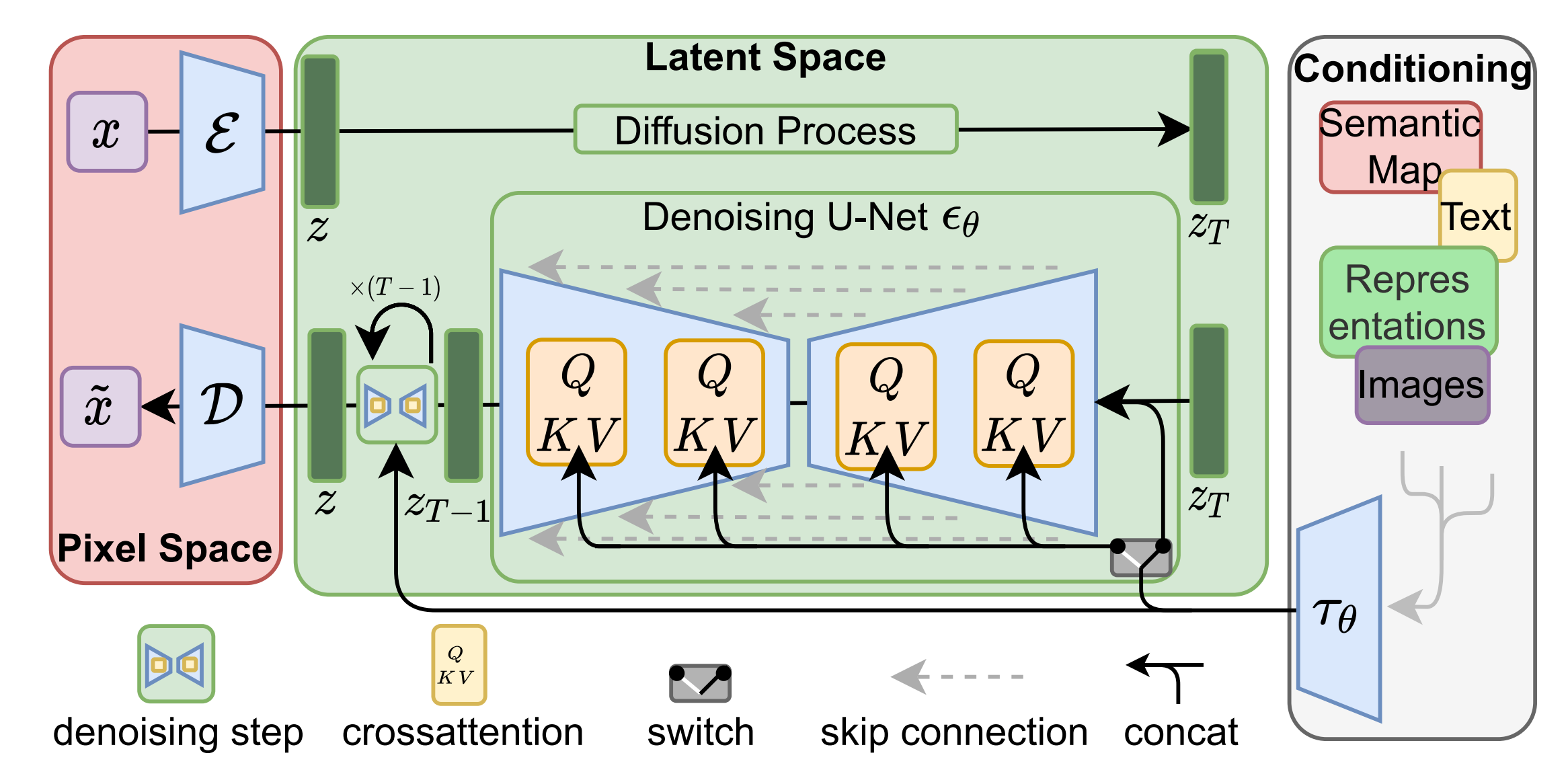
网上也有不少人画出了sora的架构图,比如来自魔搭社区的
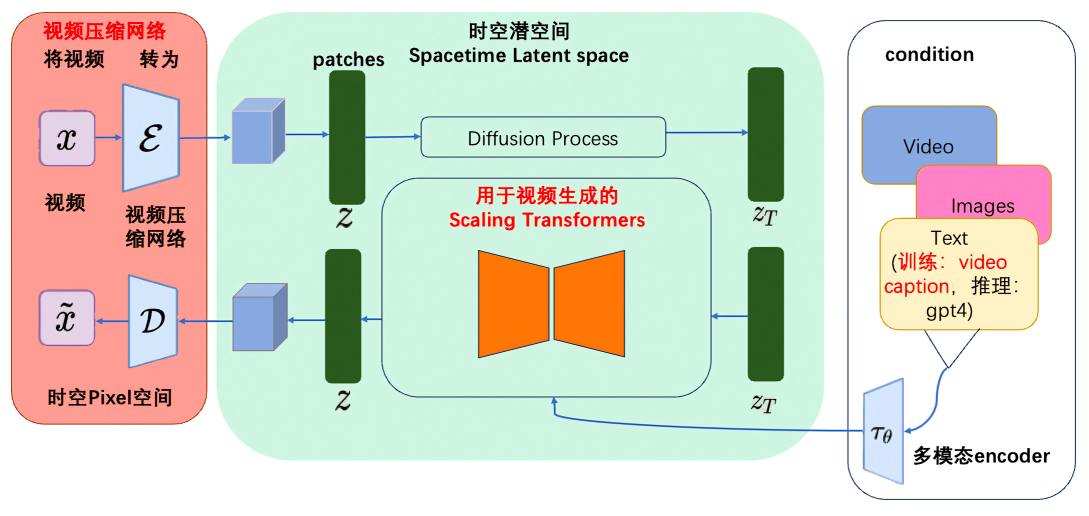
1.1.2 如何理解所谓的时空编码(含其好处)
首先,一个视频无非就是沿着时间轴分布的图像序列而已

但其中有个问题是,因为像素的关系,一张图像有着比较大的维度(比如250 x 250),即一张图片上可能有着5万多个元素,如果根据上一张图片的5万多元素去逐一交互下一张图片的5万多个元素,未免工程过于浩大(而且,即便是同一张图片上的5万多个像素点之间两两做self-attention,你都会发现计算复杂度超级高)
故为降低处理的复杂度,可以类似ViT把一张图像划分为九宫格(如下图的左下角),如此,处理9个图像块总比一次性处理250 x 250个像素维度 要好不少吧(ViT的出现直接挑战了此前CNN在视觉领域长达近10年的绝对统治地位,其原理细节详见本文开头提到的此文第4部分)

当我们理解了一张静态图像的patch表示之后(不管是九宫格,还是16 x 9个格),再来理解所谓的时空Patches就简单多了,无非就是在纵向上加上时间的维度,比如t1 t2 t3 t4 t5 t6
而一个时空patch可能跨3个时间维度,当然,也可能跨5个时间维度

如此,同时间段内不同位置的立方块可以做横向注意力交互——空间编码
不同时间段内相同位置的立方块则可以做纵向注意力交互——时间编码
(如果依然还没有特别理解,没关系,可以再看下下文第二部分中对ViViT的介绍)

可能有同学问,这么做有什么好处呢?好处太多了
总之,基于 patches 的表示,使 Sora 能够对不同分辨率、持续时间和长宽比的视频和图像进行训练。在推理时,也可以可以通过在适当大小的网格中排列随机初始化的 patches 来控制生成视频的大小
DiT 作者之一 Saining Xie 在推文中提到:Sora“可能还使用了谷歌的 Patch n’ Pack (NaViT) 论文成果,使其能够适应可变的分辨率/持续时间/长宽比”
当然,ViT本身也能够处理任意分辨率(不同分辨率相当于不同长度的图片块序列),但NaViT提供了一种高效训练的方法,关于NaViT的更多细节详见下文的介绍
而过去的图像和视频生成方法通常需要调整大小、进行裁剪或者是将视频剪切到标准尺寸,例如 4 秒的视频分辨率为 256x256。相反,该研究发现在原始大小的数据上进行训练,最终提供以下好处:
首先是采样的灵活性:Sora 可以采样宽屏视频 1920x1080p,垂直视频 1920x1080p 以及两者之间的视频。这使 Sora 可以直接以其天然纵横比为不同设备创建内容。Sora 还允许在生成全分辨率的内容之前,以较小的尺寸快速创建内容原型 —— 所有内容都使用相同的模型
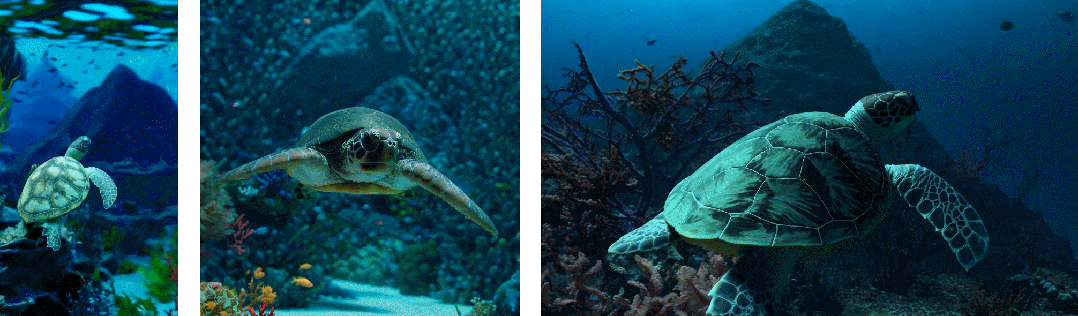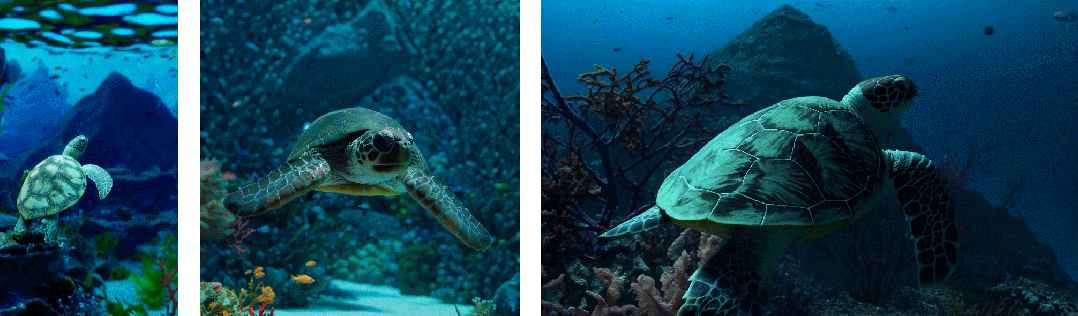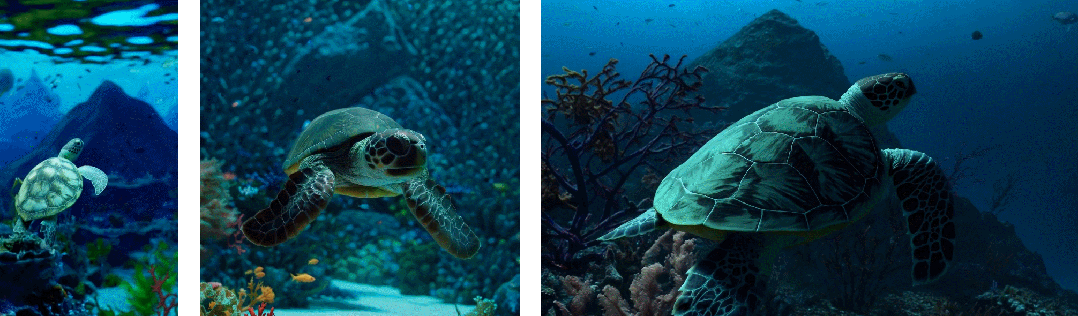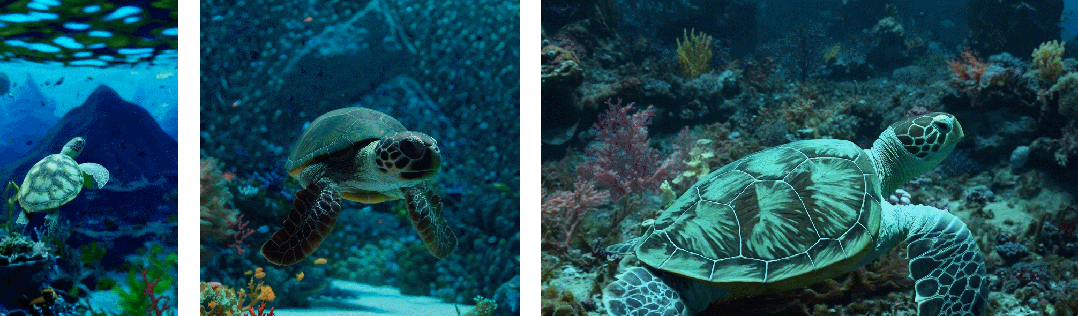
其次使用视频的原始长宽比进行训练可以提升内容组成和帧的质量
其他模型一般将所有训练视频裁剪成正方形,而经过正方形裁剪训练的模型生成的视频(如下图左侧),其中的视频主题只是部分可见;相比之下,Sora 生成的视频具有改进的帧内容(如下图右侧)

1.1.3 Diffusion Transformer(DiT):扩散过程中以Transformer为骨干网络
sora不是第一个把扩散模型和transformer结合起来用的模型,但是第一个取得巨大成功的,为何说它是结合体呢
一方面,它类似扩散模型那一套流程,给定输入噪声patches(以及文本提示等调节信息),训练出的模型来预测原始的不带噪声的patches「Sora is a diffusion model, given input noisy patches (and conditioning information like text prompts), it’s trained to predict the original “clean” patches」
类似把一张图片打上各种马赛克,然后训练一个模型,让它学会去除各种马赛克,且一开始各种失败没关系,反正有原图作为ground truth,不断缩小与原图之间的差异即可
而当把图片打上全部马赛克之后,还可以训练该模型根据prompt直接创作的能力,让它画啥就画啥
更多细节的理解请参看此文《从VAE、扩散模型DDPM、DETR到ViT、Swin transformer》
二方面,它把图像打散成块后,计算块与块之间的注意力,而这套自注意力机制便是transformer的机制

总之,总的来说,Sora是一个在不同时长、分辨率和宽高比的视频及图像上训练而成的扩散模型,同时采用了Transformer架构,如sora官博所说,Sora is a diffusion transformer,简称DiT
关于DiT的更多细节详见下文第二部分介绍的DiT
1.2 基于DALLE 3的重字幕技术:提升文本-视频数据质量
1.2.1 DALLE 3的重字幕技术:为文本-视频数据集打上详细字幕
首先,训练文本到视频生成系统需要大量带有相应文本字幕的视频,研究团队将 DALL?E 3 中的重字幕(re-captioning)技术应用于视频
具体来说,研究团队首先训练一个高度描述性的字幕生成器模型,然后使用它为训练集中所有视频生成文本字幕
与DALLE 3类似,研究团队还利用 GPT 将简短的用户 prompt 转换为较长的详细字幕,然后发送到视频模型,这使得 Sora 能够生成准确遵循用户 prompt 的高质量视频
关于DALLE 3的重字幕技术更具体的细节请见此文2.3节《AI绘画原理解析:从CLIP到DALLE1/2、DALLE 3、Stable Diffusion、SDXL Turbo、LCM》
2.3 DALLE 3:Improving Image Generation with Better Captions
2.3.1 为提高文本图像配对数据集的质量:基于谷歌的CoCa微调出图像字幕生成器
2.3.1.1 什么是谷歌的CoCa
2.1.1.2 分别通过短caption、长caption微调预训练好的image captioner
2.1.1.3 为提高合成caption对文生图模型的性能:采用描述详细的长caption,训练的混合比例高达95%..
1.2.2 类似Google的W.A.L.T工作:引入auto regressive进行视频扩展
其次,如之前所述,为了保证视频的一致性,模型层不是通过多个stage方式来进行预测,而是整体预测了整个视频的latent(即去噪时非先去噪几帧,再去掉几帧,而是一次性去掉全部帧的噪声)
但在视频内容的扩展上,比如从一段已有的视频向后拓展出新视频的训练过程中可能引入了auto regressive的task,以帮助模型更好的进行视频特征和帧间关系的学习
更多可以参考Google的W.A.L.T工作,下文将详述
1.3 对真实物理世界的模拟能力
1.3.1 sora学习了大量关于3D几何的知识
OpenAI 发现,视频模型在经过大规模训练后,会表现出许多有趣的新能力。这些能力使 Sora 能够模拟物理世界中的人、动物和环境的某些方面。这些特性的出现没有任何明确的三维、物体等归纳偏差 — 它们纯粹是规模现象
三维一致性(下图左侧)
Sora 可以生成动态摄像机运动的视频。随着摄像机的移动和旋转,人物和场景元素在三维空间中的移动是一致的
针对这点,sora一作Tim Brooks说道,sora学习了大量关于3D几何的知识,但是我们并没有事先设定这些,它完全是从大量数据中学习到的


长序列连贯性和目标持久性(上图右侧)
视频生成系统面临的一个重大挑战是在对长视频进行采样时保持时间一致性
例如,即使人、动物和物体被遮挡或离开画面,Sora 模型也能保持它们的存在。同样,它还能在单个样本中生成同一角色的多个镜头,并在整个视频中保持其外观
与世界互动(下图左侧)
Sora 有时可以模拟以简单方式影响世界状态的动作。例如,画家可以在画布上留下新的笔触,这些笔触会随着时间的推移而持续,而视频中一个人咬一口面包 则面包上会有一个被咬的缺口


模拟数字世界(上图右侧)
视频游戏就是一个例子。Sora 可以通过基本策略同时控制 Minecraft 中的玩家,同时高保真地呈现世界及其动态。只需在 Sora 的提示字幕中提及 「Minecraft」,就能零样本激发这些功能
1.3.2 sora真的会模拟真实物理世界了么
对于“sora真的会模拟真实物理世界”这个问题,网上的解读非常多,很多人说sora是通向通用AGI的必经之路、不只是一个视频生成,更是模拟真实物理世界的模拟器,这个事 我个人觉得从技术的客观角度去探讨更合适,那样会让咱们的思维、认知更冷静,而非人云亦云、最终不知所云
首先,作为“物理世界的模拟器”,需要能够在虚拟环境中重现物理现实,为用户提供一个逼真且不违反「物理规律」的数字世界
比如苹果不能突然在空中漂浮,这不符合牛顿的万有引力定律;比如在光线照射下,物体产生的阴影和高光的分布要符合光影规律等;比如物体之间产生碰撞后会破碎或者弹开
其次,李志飞等人在《为什么说 Sora 是世界的模拟器?》一文中提到,技术上至少有两种方式可以实现这样的模拟器
虚幻引擎(Unreal Engine,UE)就是这种物理世界的模拟器
它内置了光照、碰撞、动画、刚体、材质、音频、光电等各种数学模型。一个开发者只需要提供人、物、场景、交互、剧情等配置,系统就能做出一个交互式的游戏,这种交互式的游戏可以看成是一个交互式的动态视频
UE 这类渲染引擎所创造的游戏世界已经能够在某种程度上模拟物理世界,只不过它是通过人工数学建模及渲染而成,而非通过模型从数据中自我学习。而且,它也没有和语言代表的认知模型连接起来,因此本质上缺乏世界常识。而 Sora 代表的AI系统有可能避免这些缺陷和局限
不同于 UE 这一类渲染引擎,Sora 并没有显式地对物理规律背后的数学公式去“硬编码”,而是通过对互联网上的海量视频数据进行自监督学习,从而能够在给定一段文字描述的条件下生成不违反物理世界规律的长视频
与 UE 这一类“硬编码”的物理渲染引擎不同,Sora 视频创作的想象力来自于它端到端的数据驱动,以及跟LLM这类认知模型的无缝结合(比如ChatGPT已经确定了基本的物理常识)
最后值得一提的是,Sora 的训练可能用了 UE 合成的数据,但 Sora 模型本身应该没有调用 UE 的能力
更多内容请前往CSDN查看原帖 https://blog.csdn.net/v_JULY_v/article/details/136143475
该文章在 2024/2/24 14:50:00 编辑过






 400 186 1886
400 186 1886


